Wiele osób podejmuje próby programowania stron i aplikacji zapominając o podstawach. Zastanawiałeś się kiedyś w jaki sposób działają strony? Niby prosta sprawa… wpisujesz link do przeglądarki, klikasz enter, dzieje się magia i działa! Taka wiedza wystarczy osobie nietechnicznej, która jest „zwykłym” użytkownikiem Internetu. Wydaje mi się jednak, że dla programisty to zdecydowanie za mało. Warto znać chociaż podstawy, dlatego w tym artykule spróbuję opisać jak działa strona internetowa. Zaczynamy! 🙂
Domena -> DNS -> IP
Surfowanie po Internecie wydaje się być bardzo banalne. Jest to zasługa wielu inżynierów, którzy przez kilkadziesiąt lat dopracowywali technologie WWW, abyśmy mogli cieszyć się nią w takiej formie jak dziś. W działaniu strony internetowej, można wyróżnić 3 bardzo ważne elementy.
Domena
Adresy sieciowe (IP) byłyby bardzo niewygodne w codziennym, domowym użytkowaniu (choć w IT dość często się na nich operuje). Zapamiętywanie oktetów mogłoby stwarzać wiele problemów, dlatego aby ułatwić życie użytkowników zostały wymyślone nazwy domenowe. Jest to taka „ludzka” forma informacji określającej serwer. Domena działa w parze z adresem IP i nie jest jej zamiennikiem! A z czego jest zbudowana?
1. Nazwa główna
Zazwyczaj jest to nazwa firmy, osoby lub organizacji. Unikalna nazwa, która w pewnym stopniu identyfikuje zakres działalności, biznes lub usługi. Jak możesz się domyślać, im krótsza i łatwiejsza nazwa tym lepiej, ponieważ łatwiej można ją odnaleźć w sieci. Niestety, ceny za takie domeny potrafią sięgać nawet kilkudziesięciu tys. zł! Istne szaleństwo, jednak okazuje się, że może mieć ogromne znaczenie dla organizacji. Krótka i chwytliwa nazwa jest łatwa do zapamiętania i idealna do kampanii reklamowych. Dzięki temu w łatwy sposób można docierać do szerokiego grona odbiorców, a co za tym idzie przyciągać klientów i zarabiać.
W jaki sposób kupuje się domeny? Ja osobiście polecam portal OVH. Mają bardzo dobre ceny przy rejestracji, jak i przy przedłużaniu ważności, np. po roku. Niektóre firmy przyciągają klientów promocjami, tylko po to, by po roku podnieść cenę o kilkaset %. Żeby wykupić domenę, wystarczy wejść na stronę i wpisać pożądaną nazwę. Jeżeli będzie wolna, jedyne co trzeba zrobić to przejść przez proces zakupu. 🙂
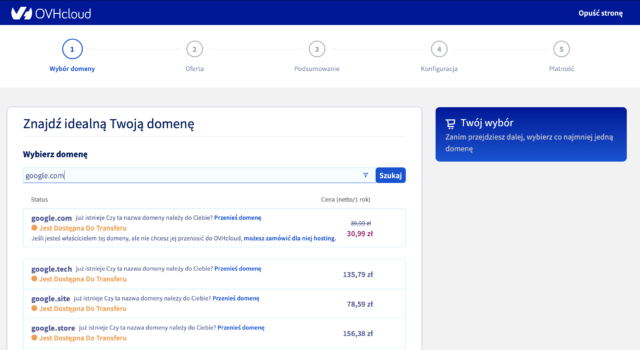
2. Rozszerzenia
Jest to gotowa, odgórnie ustalona pula, z której wybiera się interesującą nas opcję. Mogą zdarzać się przypadki, że szukana nazwa domenowa jest zajęta w opcji z rozszerzeniem .com, jednak jest dostępna w wersji .org. Dlatego warto szukać różnych opcji i alternatyw. Są one tworzone pewnymi kategoriami, np. per kraj lub przeznaczenie. Kilka przykładów poniżej:
Krajowe:
- .pl – Polska
- .be – Belgia
- .us – USA
- .uk – Anglia
- itd.
Globalne:
- .com – commercial
- .org – organization
- .biz – business
- .net – network
- itd.
3. Subdomena
Jest to dodatkowa, opcjonalna nazwa, która jest częścią głównej nazwy domenowej i występuje po jej lewej stronie. Pozwala właścicielom firm dzielić i kategoryzować swoje usługi, np. blog.xyz.com, sklep.xyz.com, mail.xyz.com. Pod każdą subdomeną może być inna strona lub zawartość. Aby utworzyć subdomenę, musisz być właścicielem domeny i mieć dostęp do konfiguratora strefy DNS.
DNS
Domain Name Services, to usługa której zadaniem jest tłumaczenie nazw domenowych na adresy IP. Działają one na specjalnych serwerach, dostępnych tylko po adresach sieciowych. Na całe szczęście, użytkownicy nie muszą mieć o nich wiedzy, ponieważ dostarczają i konfigurują je operatorzy sieciowi/dostawcy Internetu. Serwery DNS komunikują się między sobą i wymieniają informacjami o zarejestrowanych domenach. Żeby przyspieszyć proces rozwiązywania nazw na IP, w systemach operacyjnych została zaprojektowana specjalna pamięć, w której przechowywane są dane.
Kiedy powstaje nowa nazwa domenowa lub jest przypisywana do adresu IP, zachodzi tzw. zjawisko propagacji DNS, które polega na rozpowszechnieniu informacji o nowej domenie. Dane trafiają do różnych serwerów DNS, gdzie są zapamiętywane w pamięci podręcznej. Proces propagacji może trwać od kilkudziesięciu minut do nawet kilkudziesięciu godzin!
IP
Strony internetowe osadzane są najczęściej na specjalnych komputerach, nazywanych serwerami. Każde urządzenie wpięte do sieci Internet posiada dedykowany adres sieciowy, tzw. adres IP. Co to takiego? Jest to specjalny identyfikator występujący w dwóch wersjach – IPv4 (32 bity) oraz IPv6 (128 bitów). Dzięki nim możliwa jest komunikacja i wymiana danych pomiędzy różnymi urządzeniami. Możesz się zastanawiać dlaczego są akurat dwie wersje. Istnieją obawy, że pula z wersji 4 za jakiś czas wyczerpie się, co zablokowałoby rynek urządzeń z interfejsami sieciowymi (komputery, laptopy, komórki, zegarki, itd.). Dlatego równocześnie przydziela się nowszą wersję, która powinna wystarczyć na kolejne setki lat. Adresy IP można przyrównać do numerów telefonów. Każdy numer jest w pewnym sensie przypisany do konkretnej osoby. Znając go można się kontaktować i wymieniać informacjami.
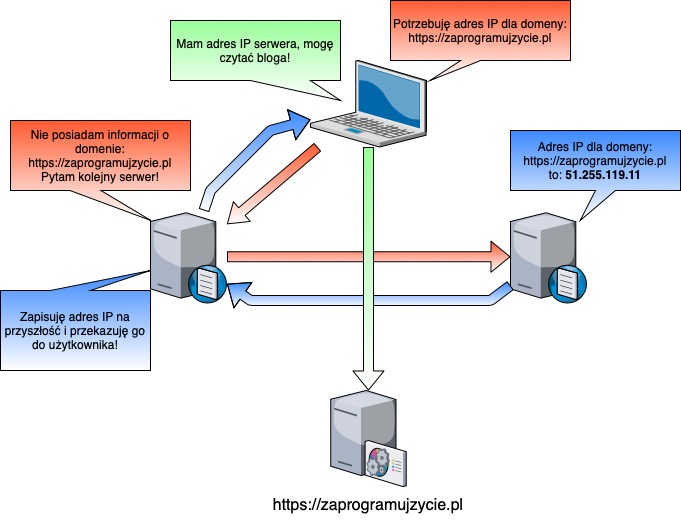
Powyższy schemat prezentuje potencjalne zachowanie przeglądarki podczas wizyty na naszym blogu. Jeżeli nazwa domenowa nie znajduje się w pamięci komputera, nie przetłumaczy jej na adres IP. Przez to odpytywany jest pierwszy serwer DNS. Jeżeli on również nie ma informacji o domenie, odpytywany jest kolejny i kolejny, do momentu uzyskania adresu sieciowego. Informacja jak po łańcuszku, tą samą drogą wraca do przeglądarki użytkownika. W ostatnim etapie odpytywany jest nasz serwer w celu pobrania strony.
HTTP i HTTPS
No dobrze… przeglądarka uzyskuje adres IP, ale w jaki sposób to co znajduje się na innym „komputerze”(serwerze) wyświetla się u mnie?
Jaka jest różnica między tytułową dwójką? Niby różni je tylko jedna literka S, ale jak bardzo ważna! HTTPS (HyperText Transfer Protocol Secure), informuje że połączenie jest szyfrowane. Ma to ogromne znaczenie szczególnie na stronach, w których podajemy wrażliwe dane, takie jak numery do kart kredytowych lub dane osobowe. Połączenia nieszyfrowane narażają użytkowników na niebezpieczeństwo kradzieży danych, np. przez osoby „podsłuchujące” sieć. Jeżeli strona WWW zawiera szyfrowane połączenie, przeglądarka po uzyskaniu adresu IP w pierwszej kolejności pobiera, weryfikuje certyfikaty SSL oraz ustala algorytmy szyfrowania. Dopiero po tym wszystkim pobiera dane z serwera.
Żądania = requesty
Przykład żądania generowanego przez przeglądarkę umieściłem poniżej. Nie chcę się teraz zagłębiać w szczegóły, ponieważ jest to dobry materiał na osobny artykuł. Teraz tylko chciałbym pokazać Ci podstawowe dane jakie są wysyłane przez przeglądarkę.
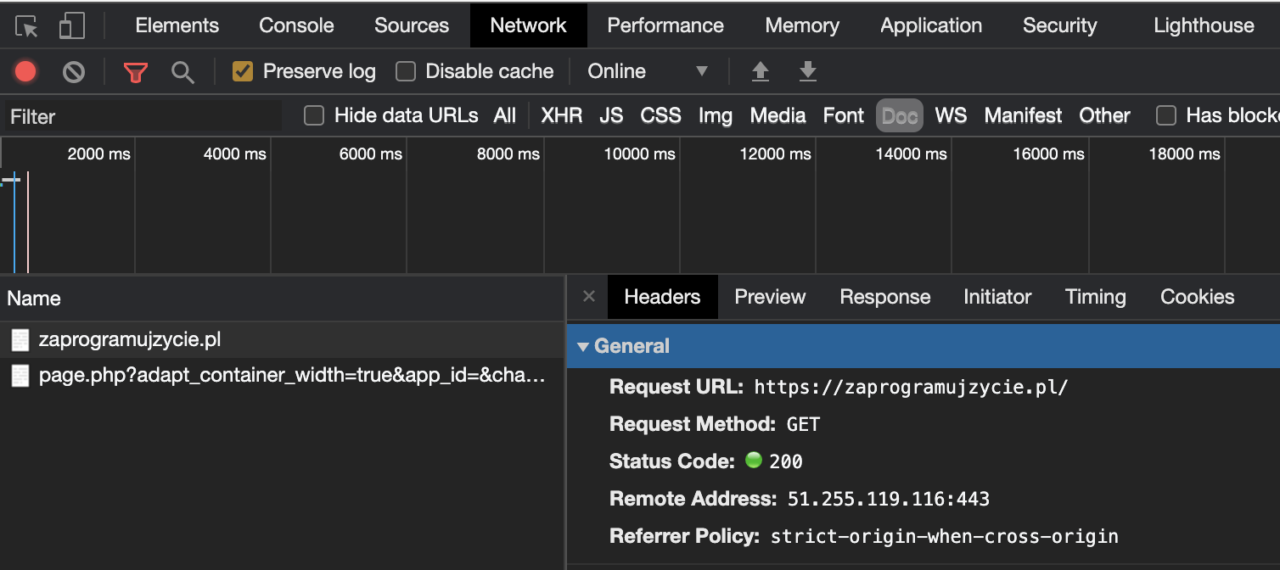
- Request URL – pełny adres URL strony WWW – protokół + domena;
- Request Method – metoda HTTP;
- Status Code – status odpowiedzi serwera (omówione poniżej);
- Remote Address – adres sieciowy serwera (IP) + port.
Metody HTTP
Metody są potrzebne do określenia jaki typ zasobu będzie pobierany przez przeglądarkę. Deweloper dzięki temu może odpowiednio sterować ruchem, który trafia do serwera. Wyróżnia się kilka najczęściej stosowanych metod:
- OPTIONS – służy do odpytywania serwera, jakie metody HTTP można wykonywać na danym zasobie;
- HEAD – jest bardzo podobna do metody GET. Różnica polega na tym, że odpowiedź nie zawiera „ciała”, tylko same nagłówki HTTP;
- POST – wysłanie informacji do serwera o utworzeniu nowego zasobu, np. dodanie produktu do sklepu;
- PUT – wysłanie informacji o utworzeniu nowego zasobu z konkretnym identyfikatorem lub nadpisanie istniejącego zasobu na serwerze;
- PATCH – wysłanie informacji aktualizujących istniejące zasoby na serwerze, np. aktualizacja ceny produktu w sklepie;
- GET – pobranie informacji z serwera, np. informacje o produkcie ze sklepu;
- DELETE – wysłanie informacji o usunięciu zasobu, np. usunięcie produktu ze sklepu.
Jest ich trochę więcej, jednak nie wykorzystuje się ich zbyt często. Wydaje mi się, że warto skupić się i opanować te powyższe. 🙂
Co ciekawe, programista aplikacji może definiować tzw. endpointy (końcówki / adresy URL) pod takimi samymi nazwami, które „nasłuchują” na różnych metodach. Oznacza to, że np. adres URL https://xyz.pl/product przy metodzie POST będzie dodawał produkt do sklepu, a przy metodzie GET pobierze listę.
Odpowiedzi = response
Podobnie jak żądanie, odpowiedź również ma ustandaryzowaną formę, a jedną z najważniejszych informacji jest typ odpowiedzi (content-type), dzięki której przeglądarka wie jak poradzić sobie oraz w jaki sposób przetworzyć otrzymaną zawartość. W ciele odpowiedzi mogą być zwracane dane w różnych formatach, np.: XML, JSON, HTML, TEXT, itd. Dokładniej przyjrzymy się temu w kolejnym artykule, poświęconym budowie protokołu HTTP.
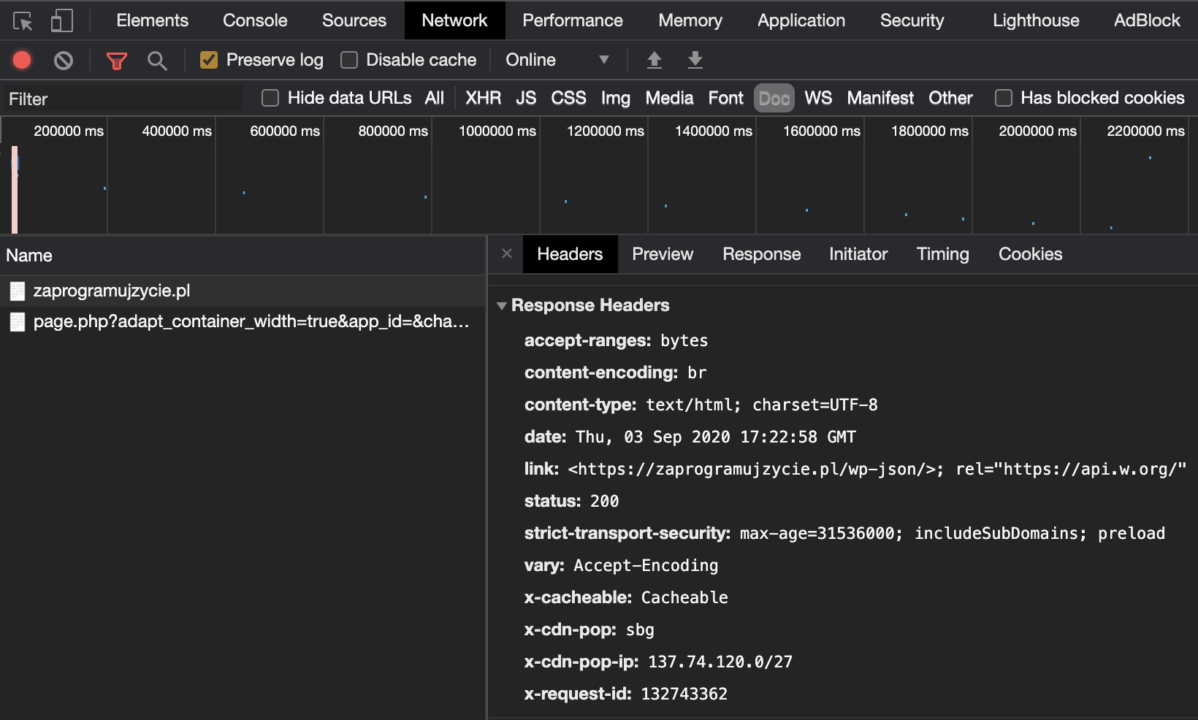
Statusy
Kolejna bardzo ważna informacja przekazywana w nagłówku odpowiedzi. Jest to trzycyfrowy kod numeryczny, który występuje w różnych grupach:
- 1xx – informuje o procesie przetwarzania żądania. Są to takie statusy pośrednie;
- 2xx – statusy sukcesu i powodzenia przetwarzania żądania;
- 3xx – informacja o zmianie miejsca żądanego zasobu;
- 4xx – błędy po stronie klienta, np. przeglądarki;
- 5xx – błędy po stronie serwera aplikacji.
Podsumowanie
Jak widzisz podczas przeglądania stron internetowych dzieje się bardzo wiele i nie jest to tak trywialne jak mogłoby się wydawać, a korzystanie z Internetu nie byłoby tak przyjemne, gdybyśmy musieli operować na adresach IP.
Daj lajka i czytaj dalej 😉
Jeżeli chcesz być na bieżąco z artykułami i jesteś ciekawy co będzie dalej, daj lajka na naszym profilu FB, a przede wszystkim zapisz się do newslettera! Spodobał Ci się artykuł? Może zaciekawią Cię inne wpisy na naszym blogu.
Dzięki za Twój czas, widzimy się niebawem! 🙂